

A Match Made in Heaven
How does a model perform when it is evaluated on a dataset that is specifically created to resonate with it's own architecture?

Large Language Models are everywhere, but what about Small Language Models (SLMs)? It’s postulated that part of ChatGPT’s power to produce coherent, fluent, and conversational text lies in its more than 1 trillion parameters. More parameters means more degrees of freedom to encode nuances learned in the training data. However, can these same emergent properties that skyrocketed ChatGPT into a household name be replicated in a much, much smaller model? That’s exactly what the Microsoft authors of TinyStories set to find out. In doing so, they have put forth a convincing argument for domain-specific learning, demonstrating the benefits of what happens when your (small) model and dataset are made for each other.
The tldr; paper review is:
TinyStories Dataset
Dataset of short stories, consisting of only words a 3-4 year old would understand
Models trained
1M-35M parameter small language models (SLMs) with 1-8 layers vs. GPT2-XL (1.5B parameters)
Varying architectures that are relatively simple and transformer-based
New evaluation scheme
Using ChatGPT-4 to grade SLM outputs
Graded SLM story completions on grammar, consistency, creativity, cohesiveness, ability to follow instructions
Findings
TinyStories can be used to successfully train models below 10M parameters to produce “a diverse set of fluent and consistent stories”
The authors observe “an emergence of reasoning capabilities, knowledge of general facts, and ability to follow certain instructions.”
Generative models trained on TinyStories exhibit properties similar to LLMs (like scaling laws, width-depth trade-offs, etc.)
This is a convincing and interesting case of domain-specific machine learning, where the domain is the same as ChatGPT — language. However, it is clear that when information in the training dataset is distilled in meaningful ways to demonstrate the domain of training and application, a model of much smaller size (order millions of parameters instead of billions) and simpler architecture is able to produce satisfying results. In turn, the authors found that because the model was much smaller, run time was faster and demanded far less computational power. They were able to train generative models on their TinyStories dataset in less than a day on a single GPU, instead of training for days on hundreds of GPUs (or even TPUs). Also, the more compact model size revealed learning patterns within the model itself during training, in part due to its simpler architecture, making it much more interpretable. In contrast, there are so many parameters in models like GPT-4 that finding meaningful patterns to elucidate precisely how the model is learning is much more challenging. Kind of like trying to find an obscure constellation on an extremely clear night, it’s a lot simpler to point to the Big Dipper, a well-known and simple celestial pattern.
In this work we have argued that TinyStories enables us to observe and study the emergence of capabilities such as generation of coherent text, reasoning and instruction following in LMs on a much smaller scale…
Dataset
In their study of SLMs, Microsoft researchers Ronen Eldan and Yuanzhi Li developed a synthetic dataset of short stories only consisting of words a typical 3-4 year old would understand, TinyStories. The goal of TinyStories is to distill language learning into its main components, without getting bogged down in swamps of content or confused with diversity of data. Similarly to how PCA decomposes a complex, multidimensional dataset into its characteristic dimensions, so too do the authors create a dataset keyed in on the representative elements of language learning, such as grammar, vocabulary, facts, and reasoning. They do so by noting how toddlers learn these elements as they first learn a language, building upon these foundational blocks towards more nuanced understanding and creation. The idea behind this is that a smaller model does not need the same breadth of training data as an LLM. In fact, it would be detrimental to train SLMs on the same dataset as LLMs because they lack the capacity to handle the complexity and vastness of these datasets, leading to nonsensical or repetitive results [Holtzman, et. al.].
Although the authors aimed to reduce diversity of training content to create a more navigable landscape for the generative model to learn its way through, diversity is a key element in generation. Models must be sufficiently robust for reliable performance, but also variable enough to generalize to unseen data (aka the bias-variance tradeoff). Variability can be learned through dataset diversity, so the model doesn’t learn the same information over and over again. However, the authors aimed for dataset diversity on par with the vocabulary of a toddler, so that the model “has a comparable ‘understanding’ of language to that of children.”
To achieve the desired level of diversity, the authors collected a vocabulary set of about 1500 toddler-level words, separated them into their general parts of speech, and instructed ChatGPT-3.5 to generate a story combining the prompt, given words and one “story feature,” like a bad ending, a twist, or a moral takeaway. Then, the story is cut-off at some point in the middle, mid-sentence, and the SLM is tasked with completing the story based on its beginning. These prompts would be intentionally cut off in the middle of a sentence to evaluate the generated grammar that came after it.
Finally, in order to complete the evaluation pipeline, which will be discussed in the next section, the authors created a complimentary dataset, TinyStories-Instruct. While TinyStories is one end of the generative pipeline, input → output, TinyStories-Instruct allows for the inverse trajectory to be graded, output → input. For each entry in the TinyStories dataset, TinyStories-Instruct includes the GPT-created story itself, plus a random subset of: the words and features used to prompt GPT-3.5 for its creation, a random sentence from the story, and an additional GPT-3.5-generated story summary. This extra set of instructions alongside each TinyStories entry allows the authors to recompose a prompt and generate a story from the trained model. These instructions are like the “truth information” or “label” in a traditionally supervised framework, allowing the authors to check the work of the trained SLM.
Evaluation
The evaluation method described above slightly diverges from the common practice. Usually, during evaluation the model is tasked with generating content that must match an expected answer. However, the authors take a different approach, leveraging GPT-4 to grade SLM-generated completion of stories from manually-prepared, GPT-3.5-created prompts. GPT-4 scores the generated completion on grammar, creativity, and consistency, and assigns an associated age group to the level of produced writing. The trained SLM model generated 10 completions, with the GPT-4 scores averaged over all outputs at each training step.
For the TinyStories-Instruct evaluation pipeline, GPT-4 is provided the generated story and corresponding instructions and assigns a consistency score between the two, quantifying instruction-following capabilities. The authors also asked GPT-4 to evaluate the plot coherency.
The authors note general trends in the results for the evaluation of trained models, going more into depth in the learned qualities of the SLMs in the following sections. The bulleted list of insights are summarized below for the various architectures:
Shallower models perform better in grammar than consistency.
Grammar scores plateau earlier than consistency and creativity.
Grammar can be replicated successfully by shallower models, less so consistency and creativity.
Consistent text completion based on the story beginning only emerges somewhere between hidden model sizes 64 and 128.
Creativity improves more substantially with larger model and dataset sizes (comparing SLM of 80M parameters to GPT-4 performance).
Models without hidden layers struggle with instruction-following.
Because of the generative nature of the evaluation pipeline, it’s hard to define exactly what goes into the three story scores (grammar, consistency, creativity) and the meta-scores (instruction, plot). Human evaluation would also have a similar issue, but could be quantified with a rubric or more precise sub-metrics. Perhaps this is part of the reason why SLMs seemed to do relatively better in grammar than the other two scores — grammar is a more well-defined concept, with rules to follow. Determining if a piece is more or less creative is a much squishier concept, and would need more knobs, or degrees of freedom (like GPT-4), to more convincingly replicate. I wonder if human addition in this evaluation pipeline, or replacement, would appreciably alter these conclusions or reinforce them. More specific performance insights and case studies of individual outputs are discussed in the next section, focusing on three areas: in-language aspects (knowledge, reasoning, context), meta-language aspects (instruction-following, out-of-distribution generation), and diversity of generated content.
Performance
Knowledge, reasoning, and context tracking
To track factual knowledge, reasoning, and consistency, the authors provided examples of completions from models with various architectures, and (assumingly) hand-graded the completions “according to their success…, failure…, or partial success.” As expected, factual knowledge of the generated stories increased with both the embedding dimension (akin to number of nodes in a layer) and number of layers. Worth noting is that the authors compared this facet of performance to that of GPT2-XL, which has more parameters than the largest SLM by two orders of magnitude. This largest model did not show an appreciable increase in either correct contextualization (nonsensical outputs) or factual correctness. In fact, its performance was worse than some of the SLMs in these categories.
The authors also point out a difference in trends for knowledge and context tracking: models with more layers did better at correct contextualization, while models with a higher embedding dimensions were better at factual knowledge, suggesting that “the embedding dimension is more crucial for capturing the meaning and the relations of words, while the number of layers is more crucial for capturing long-range dependencies in the generation.” This is an interesting trend to note and perhaps merits a more throughout study to see how different aspects of network architecture influence different aspects of successful language generation (at least in regards to these metrics).
As far as reasoning insights go, the authors checked for “basic reasoning abilities, such as cause and effect and elimination.” These abilities fall into the first level of causal reasoning, as outlined by Pearl: association. Arguably, elimination could fall into the second level, Intervention (what would happen if element A was not part of a set C?). Overall, the model is tasked with associating a certain outcome based on the preceding text. It is clear that even models with billions of parameters can still fail this basic step of causal learning, but smaller networks (specifically 33M parameters, 4 layers) that are more attuned to exactly what needs to be causally learned, outperforming their larger counterparts.
Instruction-following and out-of-distribution generation
The author also tracked metrics that quantified the model’s meta-language abilities: specifically in terms of following instructions and plot cohesiveness. Both these aspects improved with a larger embedding dimension and increased number of layers, according to the handful of examples given. To evaluate the capacity for the model to produce stories outside of the training domain, the authors construct a third dataset, TinyStories-Instruct-OOD. This is similar to the TinyStories-Instruct dataset, except it is prohibited to have the required words and summary appear together in the instructions that precede a story. The authors then evaluated the generated story on: following the summary and including the required words that are supposed to be matched for the original set of instructions.
Surprisingly, the model was able to achieve both the inclusion of required words and following the summary if only one set of information was provided. An example of this type of OOD story generation is shown in Figure 13 in the paper. Although, maybe it is not so surprising that the model was able to achieve this. In the previous section, the authors established that models of a certain size were successfully able to create associations and eliminations, studying the model’s basic reasoning capabilities. Looking at the given summary and required words in Fig. 13, one can see that there are opposites and close associations included between the two instructional components (ie “sad” in the required words and “happy” in the summary). So while the model does not necessarily need the exact information to reproduce a sufficient output, it has been shown that it is able to make the sufficiently correct connections between parts of speech that are perhaps more abstract that simple grammar: associations in theme. This is similar to the goal of an Latent Dirichlet Allocation (LDA) model, which aims to “summarize” the given text into overall themes by creating probabilistic connections at different levels of the corpus. I wonder if the SLM operates in a similar fashion, or leverages similar distributions, “under the hood” to achieve this OOD generation.
Diversity of generated content
The authors cite diversity of the generated stories as one of the biggest challenges of text generation. Interestingly, the authors define diversity by its lack, or seeming opposite: memorization, which can be viewed as a type of bias, penalizing the model from straying too far from the given training data. Diversity itself is a slippery aspect to quantify, characterize, or rank. Using memorization not just as a proxy for diversity, but as an inverse — something to “avoid or detect” — provides not only a more intuitive basis, but also a mathematical one, for the evaluation of this quality. Therefore, the authors pay close attention to the diversity of the SLM-generated outputs — diversity is carefully defined by different types of memorization, with different methods and metrics to qualify or quantify almost every type.
The three types of memorization to key in on are:
exact memorization: copy-pasting
simple template matching: substituting words or phrases but maintaining overall structure and style
complex template matching: maintaining general plot lines and themes but changing story details
The first two types of memorization are straightforward to analyze and are done so with the methods below. However, the authors claim that this last type is the most difficult to assess, “as it requires a deeper understanding and analysis of the content and the meaning of the stories, and how they relate to each other.”
I think diving into this last type of memorization would not only provide another handle on SLM performance, but also would help elucidate behavior within the model, picking out what the model actually learns and deems important from the prompts and training material. Maybe some domain expertise in linguistics or education would be helpful here in crafting some metrics and methods to estimate complex template matching. Or you could employ meta-algorithms like LDA on the input and output stories to analyze the consistency in overall themes and distributions of semantics.
In this case, the authors apply three methods for evaluating the first two types of memorization:
Manual inspection: inspecting the model output from human-generated input
Completion of training stories: inspecting the model output from truncated training stories
Diversity of instructions: alter the instructions of TinyStories-Instruct (with words not included in the training data)
ROUGE score analysis: inspecting word and n-gram overlap
I can appreciate the diversity of assessment this suite of tests cover — from direct human intervention to aggregate quantification. One of the most important considerations in DSML is not just viewing machine learning as a decision-maker, but leveraging DSML tools to inform the user, as recommendations to guide the search and hypothesis space the learning algorithm traverses, searching for the optimal answers [Nero, Shan]. Therefore, DSML necessitates human intervention. This is exactly achieved by the first method. I could argue that the second and third methods also satisfy this, depending on how the differences are evaluated. These two methods get at two different types of ways the training could cause memorization (or allow for diversity): from the training data itself or from the “labels” included in TinyStories-Instruct.
Finally, simple (and also, by subsumption, exact) template matching is measured quantitatively with a ROUGE score analysis. The ROUGE score counts the number of overlapping n-grams or words (1-grams, unigrams) between computer-generated summaries [Lin]. The ROUGE score has a domain of [0,1], with higher values indicating more similarity between the texts. The ROUGE-k precision score used in TinyStories is

where T1 and T2 are the texts to analyze and Gk(Ti) is the k-gram from text Ti. The authors combine precision scores into an f-measure as well,

Then, the authors construct an experiment similar to the completion of training stories method, where training stories are randomly sampled, cut in half, and then the model creates a completion to the bisected training story. Several comparisons are made: the latter half of the training story to the generated completion, the generated completions to each other, the generated completions to the training set (in terms of k-grams and whole texts).
Across all these methods and metrics, the authors do not find convincing evidence of exact memorization or simple template matching between the SLM-generated stories, and the training datasets, “provid[ing] strong evidence that our models produce genuinely novel and diverse stories, rather than simple variations of existing stories.”
Interpretability
Interpretability is an interesting research area in AI and AI safety. Especially with the advent of large language models, understanding model function is becoming increasingly important. Picking apart systems as complex and nonlinear as neural networks, let alone those with billions or trillions of parameters, is no small feat. However, if the network was a more manageable size, perhaps it would be easier to glean some insight into its learning process. The TinyStories authors present preliminary evidence that this may be the case.
In this paper, the authors only briefly examine the role of the attention head and MLP in the network. The role of attention heads are analyzed in the context of distance-based and semantic-based attention. The distance-based analysis is short and attention maps are presented in Fig. 19 of the paper. However, the authors note that certain parts of speech, (ie articles like “the” and “a”) and n-grams that fulfill a similar role (ie “,”) are induced by distance-based, local attention heads. This remark makes sense because, as the authors note, these tokens depend on “short-range interactions within a single sentence.” Another attention head handled the words that were more global to the overall story, like character names and places.
To analyze the MLP neuron tracking, the authors monitored the activation value of specific neurons after a trained model has processed a corpus of text. The tokens with highest activation value for a given neuron are singled out as the most significant. The authors chose two neurons to track, importantly pointing out that because of the network’s permutation invariance, “taking the two first neurons is the same as taking an arbitrary choice of two neurons.” The authors present generated text with the most significant token for a given neuron in a layer highlighted for two neurons in the last layer of a 1M-parameter model (top row of Fig. 21), the first neuron in another layer (bottom left), and the neuron with the largest activation values over all neuron-token combinations (bottom right). Interestingly, this last neuron picked out the character names as the most significant token, indicating from the neuron’s local significance and the globally large activation value that these tokens are important to the story. The types of sentences that these tokens appear in also seem to be the first sentences of the generated text. The two neurons in the last layer picked up on pronouns and verbs separately, while the neuron in the penultimate layer selected adjectives. These results preliminary demonstrate that certain roles of writing and narrative-building can potentially be traced back to self-contained components of an SLM. To support that this type of interpretability is more specific to smaller models, the authors analyzed the activation values of a GPT-2XL with the same method and did not find that the same kind of semantic patterns emerged. It would be interesting to further dive into this analysis from this springboard, creating distributions of different parts of speech and their associated activation values for different areas of the network and at different training steps to monitor the learning of the network as it’s optimizing itself.

Architecture Exploration
Determining the optimal model architecture for a given task is mostly achieved through trial and error or some kind of meta-heuristic. The authors study the model performance measured in flops (floating-point operations per second) as a function of model size, noting that previous works have modeled this trend as a polynomial scaling. However, the models of these previous works were orders of magnitude larger than the SLMs studied here, with training datasets to match. Yet, the authors claim to observe a similar polynomial trend with the limited data points they collected, varying the number of SLM hidden dimensions and layers, seen below in Figure 23 from the paper.
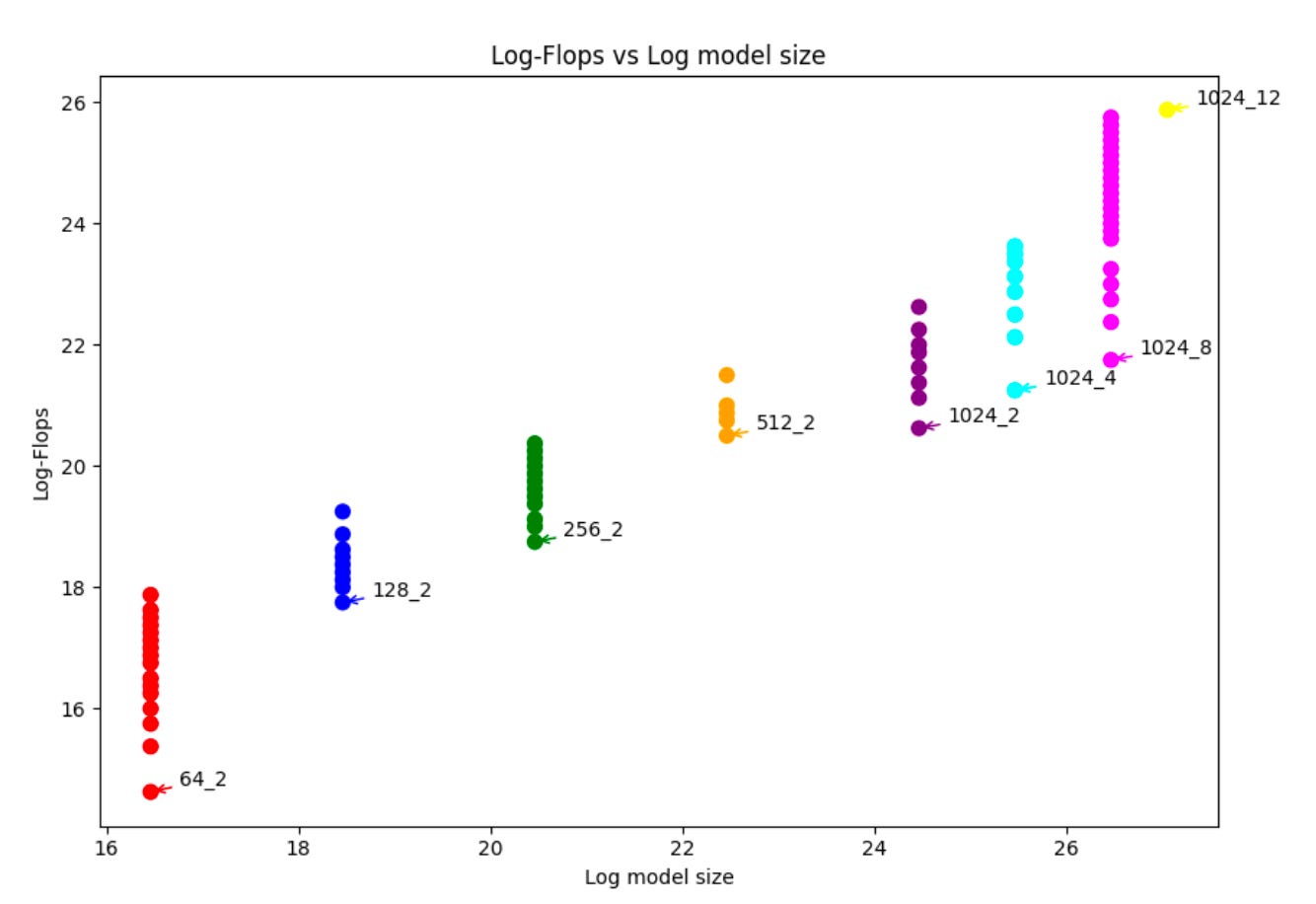
The authors also do a similar study analyzing the effect of the number of attention heads on performance. As expected, with an increasing number of heads, and layers, the model was able to do better across the language performance metrics. Being able to observe trends like these in terms of two aspects of model architecture demonstrates the sensitivity of the SLMs and training dataset, and suggests that “there might be a universal phenomenon here.”
We hope that TinyStories can facilitate the development, analysis and research of LMs, especially for low-resource or specialized domains, and shed light on the emergence of language capabilities in LMs.
I think the most promising aspect of studying smaller LMs like these is the interpretability potential. Being able to look inside a model and draw connections between activated neurons or model segments and reproducible results could potentially lead to a better understanding of learning at much larger scales. It would be interesting to see at what order of model magnitude this learning becomes obscured. Of course, as evidenced by these findings, that would mean scaling the size and complexity of the dataset accordingly. Maybe slightly larger models would be better suited for grade-school stories, five-paragraph AP English essays, and eventually college-level arguments.
Regardless of what you found most interesting, one takeaway is clear: small models matter too! Studying smaller models seems like an obvious route, but that doesn’t take away from their importance. In fact, smaller models more clearly illuminate their domain-specific capabilities.
When I start a large code framework (or more realistically, when I need to debug one), I take away abstractions and flourishes that may obscure function. I recreate a simple case of what I need to examine before scaling up. This also includes running on a reduced dataset, to not get caught up in statistical fluctuations or data idiosyncrasies. Whenever I charge on with constructing the framework, I almost always regret not testing the smaller, more specific, iterations first. Like looking for the Big Dipper, solutions are a lot easier to find without extraneous starlight. Focusing on understanding small language models, run with their compatible dataset, could be the guiding light we need to more deeply understand and audit the larger one(s) that are being used more and more everyday.